在數字經濟時代,數據已成為驅動業務增長的核心生產要素。面對日益復雜的應用場景和海量數據洪流,傳統數據庫架構在資源彈性、成本控制以及運維復雜度方面面臨嚴峻挑戰。阿里巴巴集團作為全球領先的科技企業,其新一代數據庫技術正致力于突破這些瓶頸,通過架構革新與技術融合,實現業界領先的“極致彈性”能力,為云原生時代的數據服務樹立新標桿。
一、 核心挑戰:為何需要“極致彈性”?
傳統數據庫的彈性往往受限于單機硬件上限和主從架構的切換延遲。在電商大促、內容熱點爆發等場景下,業務流量可能在短時間內出現數個數量級的劇烈波動。如果數據庫無法快速、平滑地擴縮容,企業要么承受高額的成本浪費(為峰值過度預留資源),要么面臨服務不可用、用戶體驗受損的風險。因此,一種能夠按需、實時、無感地調整計算與存儲資源的能力,即“極致彈性”,成為現代數據庫服務的剛需。
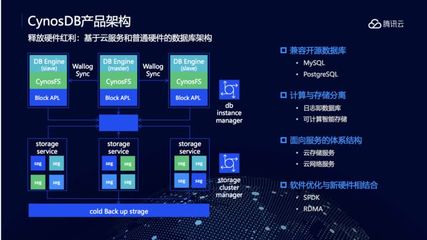
二、 架構基石:計算與存儲的深度解耦
阿里新一代數據庫實現極致彈性的核心,在于其革命性的“計算與存儲分離”架構。
- 計算層無狀態化:將負責SQL解析、優化、執行的數據庫引擎(計算節點)設計為無狀態或輕狀態。計算節點不再本地綁定特定的數據塊,而是成為一個純粹的“處理器”。
- 存儲層池化與共享:數據持久化在分布式、高可用的共享存儲池中(如PolarStore)。該存儲層具備極高的IOPS、帶寬和容量擴展能力,并通過多副本、RDMA網絡等技術確保數據的強一致性與低延遲訪問。
- 分離的優勢:此架構下,計算資源的擴容可在秒級內通過增加計算節點完成,無需進行耗時的數據遷移。縮容同樣迅速,釋放的資源可立即被其他服務使用。存儲則可根據數據量獨立、平滑地擴展,真正實現了計算與存儲資源的獨立彈性伸縮。
三、 關鍵技術:實現彈性的核心引擎
在解耦架構之上,多項自研技術共同鑄就了彈性的“發動機”:
- 智能資源調度與彈性策略引擎:系統實時監控負載指標(如CPU、內存、IO、連接數),結合預測算法(如基于時間序列或機器學習的流量預測),自動觸發彈性擴縮容決策。用戶亦可設置基于規則的自定義彈性策略。
- 高速鏈路與一致性協議:計算節點與共享存儲之間通過高性能網絡(如RDMA, Remote Direct Memory Access)互聯,極大降低訪問延遲,使得遠程訪問數據的性能逼近本地SSD,這是保障彈性后性能不降級的關鍵。優化的分布式一致性協議確保了跨節點數據訪問的準確與高效。
- Serverless化與按需計費:將數據庫服務推向更深層次的Serverless模式。用戶無需預先配置實例規格,數據庫服務能夠自動根據實際負載,在毫秒到秒級內動態分配和調整計算資源,并實現按實際使用的資源量進行計費,將成本優化做到極致。
- 在線與無感的數據遷移與重分布:即使在彈性伸縮過程中,也能保證業務連接不中斷、事務不丟失。通過邏輯復制、增量日志同步等技術,實現數據在存儲層或跨計算節點的平滑再平衡,對應用完全透明。
四、 場景賦能:彈性帶來的業務價值
極致彈性能力已廣泛應用于阿里經濟體內外:
- 應對峰值流量:在“雙11”等全球最大規模的流量脈沖中,數據庫集群可在幾分鐘內完成數倍甚至數十倍的計算能力擴容,活動結束后快速縮容,資源利用率大幅提升。
- 支持敏捷開發與測試:開發測試環境可以按需創建、快速擴容,任務完成后立即釋放,極大提升開發效率并降低環境成本。
- 助力企業降本增效:對于中小企業和初創公司,Serverless模式使其能夠以極低的啟動成本獲得與大型企業同等級別的數據庫能力,并只為真實流量付費。
- 實現混合負載整合:一套彈性架構可同時高效處理在線事務處理(OLTP)與在線分析處理(OLAP)的混合負載,根據優先級動態調配資源,簡化技術棧。
五、 未來展望
阿里新一代數據庫的彈性演進并未止步。未來的方向將更加聚焦于:
- 更細粒度的彈性:從實例級彈性向內核級、甚至算子級彈性深化,實現更精準的資源匹配。
- 跨地域與多云彈性:在混合云、多云架構下,實現數據與計算能力的全局智能調度與彈性分布。
- AI驅動的全自治彈性:深度融合AI運維(AIOps),實現從性能診斷、瓶頸預測到彈性動作的全鏈路自動閉環,向“自驅、自愈、自優化”的自動駕駛式數據庫邁進。
###
阿里新一代數據庫技術通過底層架構的根本性重構與一系列前沿技術的深度融合,將數據庫的彈性能力推向了一個新的高度。這不僅僅是技術的突破,更是云原生時代對數據庫作為服務核心基礎設施的重新定義。極致彈性意味著更強大的業務支撐力、更優的資源利用率與更低的總體擁有成本,它正驅動著各行各業加速數字化轉型與創新步伐。